MimicMotion——姿势指导的高质量人体运动视频生成

MimicMotion 是由腾讯开发的一个可控视频生成框架,通过自信度感知姿态引导生成高质量的人体运动视频。该模型结合了图像到视频扩散模型和姿态序列引导,能够生成任意长度的视频,并在时序平滑度和细节丰富度上表现出色。它通过区域损失放大和逐渐潜在融合策略,显著改善了视频质量和模型的鲁棒性。
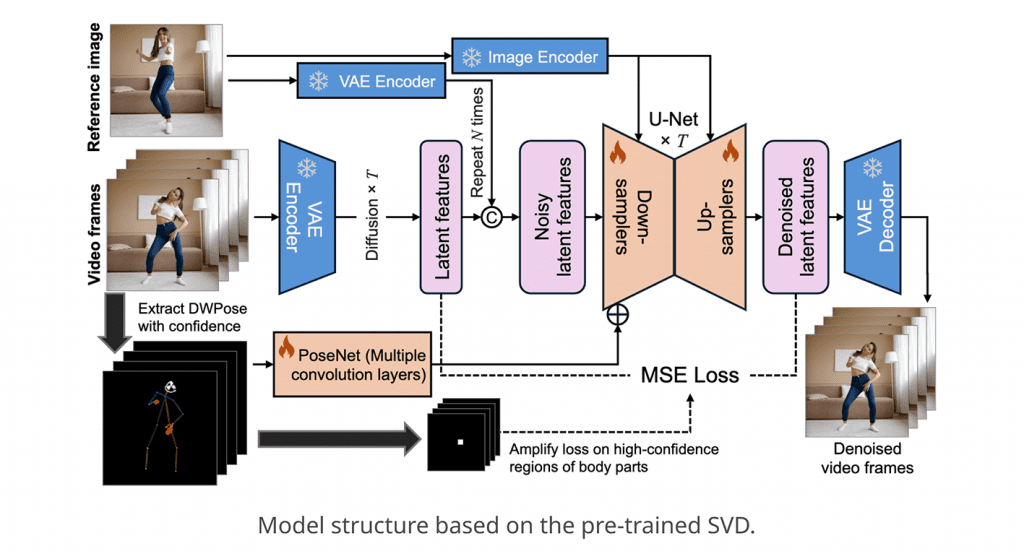
MimicMotion将图像到视频扩散模型与新的置信度感知姿势引导相结合。该模型的可训练组件包括时建功能包括:1)姿空U-Net和PoseNet,用于将姿势序列作为条件引入。置信度感知姿势引导的关销势序列伴随着关键点置信度分数,使模型能够根据分数自适应调整姿势引导的影响。2)有在损失函数中,具有高置信度的区域具有更大的权重,从而在训练中放大它们的影响。
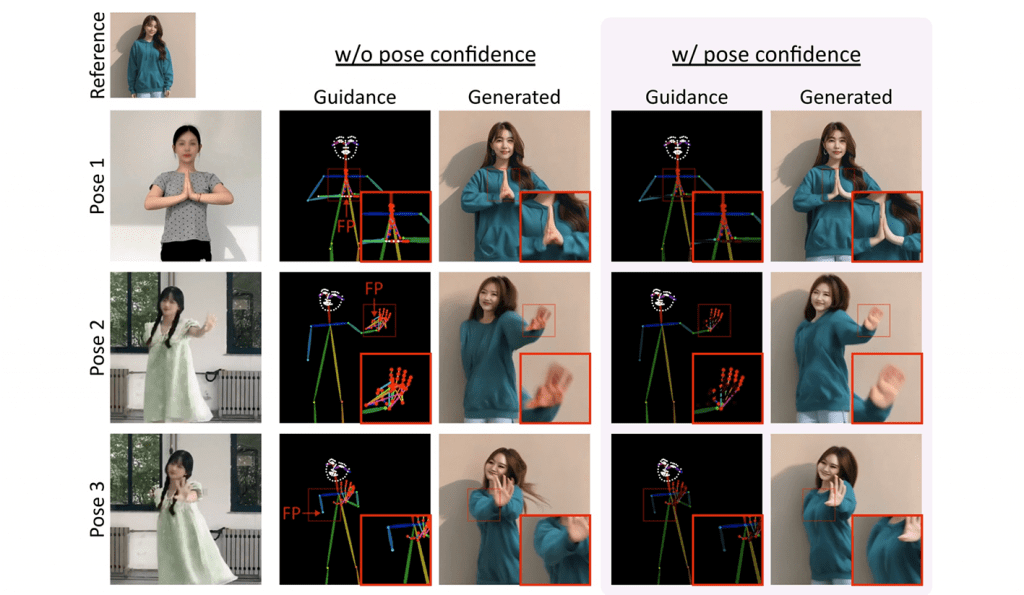
消融研究:信任感知姿势引导,此设计增强了对错误引导信号(姿势1&2)的生成鲁棒性,并提供了可视性提示以解决姿势(姿势3)。
官方网址:https://tencent.github.io/MimicMotion/
本站的信息资源大部分源自公共网络,由于信息来源众多故不特标注来源网址和原作者,如果有疑惑请及时联系站长,站长对建议做出相应调整,感谢。