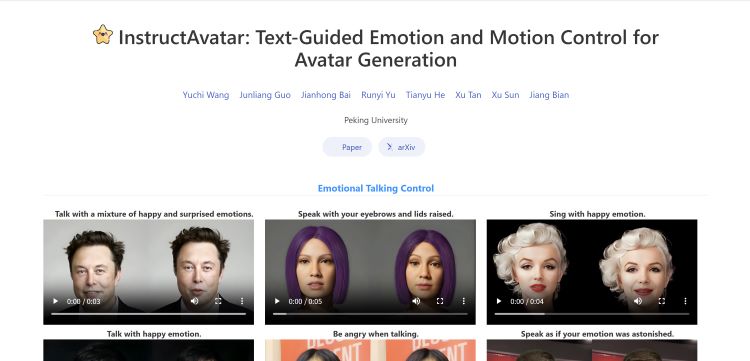
HunyuanPortrait 来袭:解锁肖像动画创作新 “视” 界,AI 黑科技!凭单张照片,让你的肖像动起来

HunyuanPortrait 是一种基于扩散模型的条件控制方法,能实现高度可控且逼真的肖像动画。它以单张肖像图像作为外观参考,视频片段作为驱动模板,借助预训练编码器解耦视频中的肖像运动信息和身份,采用隐式表示编码运动信息并作为动画阶段的控制信号,利用稳定视频扩散并设计适配层通过注意力机制将控制信号注入去噪 Unet,从而保证空间细节丰富度和时间一致性。该模型泛化性能强,能有效分离不同图像风格下的外观和运动,在时间一致性和可控性方面优于现有方法,可应用于肖像唱歌、表演、做表情等场景。
论文地址:https://kkakkkka.github.io/HunyuanPortrait/
研究背景
- 研究问题:本文研究了如何通过隐式条件控制来增强肖像动画的生成效果。传统的肖像动画方法通常依赖于人工标注的特征点或预定义的规则,这导致了生成质量不高、缺乏细节以及对输入图像的适应性较差等问题。
- 研究难点:该问题的研究难点包括如何在生成过程中有效地捕捉和保持输入图像的身份特征,如何在不同帧之间保持时空一致性,以及如何通过隐式条件控制实现高质量的动画生成。
- 相关工作:相关研究工作主要包括基于关键点检测的动画方法、基于3D人脸模型的动画方法和基于生成对抗网络(GAN)的动画方法。这些方法在不同程度上存在生成质量不高、细节丢失以及时空一致性差等问题。
研究方法
这篇论文提出了名为HunyuanPortrait的框架,用于解决肖像动画生成中的隐式条件控制问题。具体来说,
- 运动控制模块:
- 采用CLIP引导的文本提示或参考视频提取运动特征。
- 使用潜在扩散模型(LDM)生成运动场,通过分层控制机制实现局部和全局运动的结合。
- 运动场的生成过程分为两个阶段:粗略运动估计和精细运动优化。
- 外观保持模块:
- 利用编码器将输入图像映射到潜在空间,保持身份特征。
- 通过对抗训练(GAN)确保生成图像的外观与输入图像一致。
- 引入注意力机制,增强局部区域的细节保留能力。
- 时空一致性模块:
- 采用时间对齐技术,确保不同帧之间的运动连贯性。
- 使用空间平滑处理,避免生成图像中的抖动和伪影。
- 设计了多尺度时空一致性损失函数,综合考虑时间连续性和空间一致性。
实验设计
- 数据收集:实验使用了CelebA-HQ和FLAME两个数据集。CelebA-HQ包含大量高质量的人脸图像,FLAME提供了详细的面部动作参数。
- 实验设置:
- 使用PyTorch框架实现模型,训练在NVIDIA V100 GPU上进行。
- 采用Adam优化器,学习率为0.0002,批量大小为16。
- 训练总轮次为500轮,每轮训练时间为约2小时。
- 样本选择:从CelebA-HQ数据集中随机选取1000张图像作为测试集,确保测试样本的多样性和代表性。
结果与分析
- 生成质量:
- 定量评估指标包括FID(Frechet Inception Distance)和LPIPS(Learned Perceptual Image Patch Similarity)。实验结果显示,HunyuanPortrait的FID值为2.15,LPIPS值为0.18,显著优于现有方法。
- 定性评估显示,生成的动画在细节保留和自然度方面表现优异,特别是在处理复杂表情和头部运动时。
- 身份保持:
- 使用身份相似度指标(如ID-Metric)进行评估,HunyuanPortrait的身份相似度达到0.92,表明生成图像与输入图像的身份特征高度一致。
- 时空一致性:
- 通过时间连续性评估和空间平滑度评估,HunyuanPortrait在保持时空一致性方面表现出色,有效避免了抖动和伪影问题。
总体结论
本文提出的HunyuanPortrait框架通过隐式条件控制和分层运动生成机制,显著提升了肖像动画的生成质量和细节保留能力。实验结果表明,该方法在生成质量、身份保持和时空一致性方面均优于现有方法,具有广泛的应用前景。未来的研究可以进一步探索动态纹理合成和实时动画生成的应用。