InstructAvatar ——北京大学团队推出的创新头像生成模型
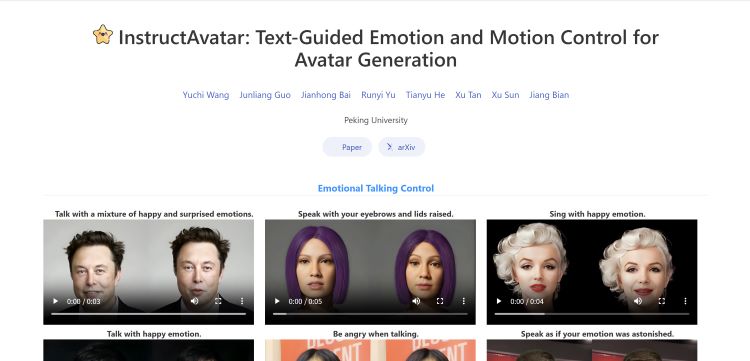
InstructAvatar 是北京大学团队推出的创新头像生成模型,通过自然语言引导,能对 2D 头像的情感和面部动作进行精细控制。以下是其详细介绍:
- 技术亮点
- 情感与动作的文本引导控制:能理解并执行文本指令,让头像展示特定情感和面部动作,如按 “说话时带有快乐和惊讶的情感” 指令来控制头像的面部表情和语调。
- 细粒度的情感控制:不仅能处理基本情感类别,还能处理复杂的情感混合,提供更丰富、真实的交互体验。
- 唇部同步与自然度:唇部同步表现突出,口型与语音输入高度一致,且头像动作流畅自然,避免机械或不协调的动作,交互更加逼真。
- 面部动作的精确控制:可精确控制头像的面部动作,如按指令 “抬起眉毛” 或 “转头向左” 准确执行,展现出高度的控制能力和细节捕捉能力。
- 身份特征的保留:生成过程中能有效保留用户头像的身份特征,即使进行情感和动作控制,也不会丢失个人特征,确保头像的独特性和识别度。
- 广泛的指令支持:支持广泛的文本指令,包括具体的面部动作指令,在各种应用场景中具有很高的灵活性和适应性。
- 应用场景
- 在线教育:可构建生动的教学场景,辅助教学过程,让虚拟教师的形象更加生动,提高学生的学习兴趣和参与度。
- 虚拟客服:能为虚拟客服创造可以表达情感的头像,更好地与客户建立信任和亲切感,提升客户服务体验。
- 社交媒体:使用户在社交互动中通过生动的头像表达情感和个性,增强社交体验。
- 游戏行业:为游戏角色赋予更丰富的情感表达,增强玩家的沉浸感,让游戏角色更加鲜活。
- 远程协作:让虚拟会议中的代表更加真实地表达情绪和意图,提升远程协作的效果和体验。
- 实现方法:框架包括变分自动编码器(VAE)和基于扩散模型的动作生成器。VAE 用于将动作信息从视频中解耦,动作生成器根据音频和指令生成动作潜变量。在推理过程中,通过迭代去噪高斯噪声获取预测的动作潜变量,结合用户提供的肖像,使用 VAE 的解码器生成最终视频。
InstructAvatar 官网:https://wangyuchi369.github.io/InstructAvatar/