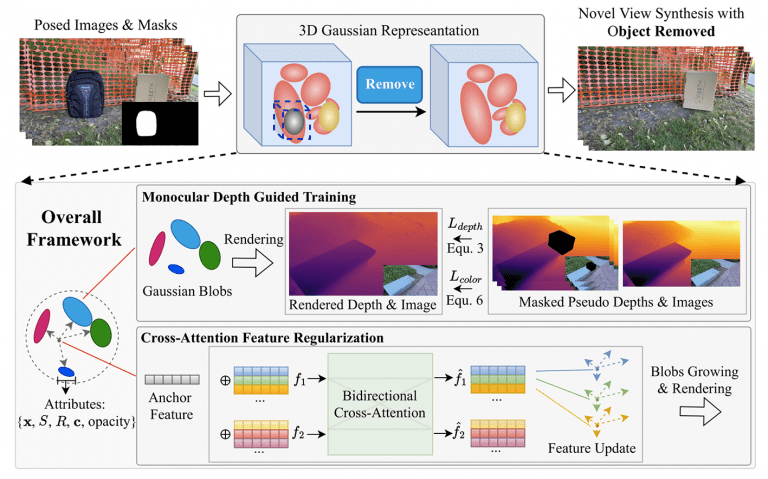
Wonderland扩散模型的从单图生成完整的3D场景
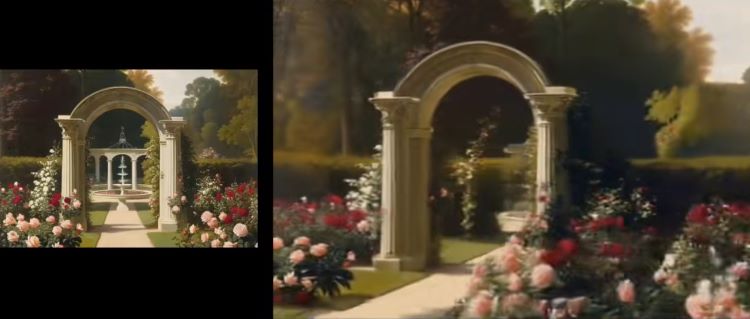
Wonderland,是一款在人工智能领域内,基于视频扩散模型开发的创新框架。它具有独特且强大的功能,能够从任意单张图像出发,生成完整的 3D 场景。在 3D 场景生成领域,以往的技术常常面临诸多难题,尤其是不可见区域的空间扭矩问题,这一问题严重影响了生成场景的 3D 一致性和完整性。而 Wonderland 框架的出现,为解决这一难题提供了全新的思路与方法。
Wonderland 采用了渐进式策略来训练 3D 重建模型。这一策略并非一蹴而就,而是通过逐步推进、不断优化的方式,让模型在训练过程中逐渐学习到图像与 3D 空间之间的复杂关系。在训练初始阶段,模型对单张图像所蕴含的 3D 信息理解有限,生成的 3D 场景可能存在诸多瑕疵。然而,随着渐进式训练的深入,模型不断吸收新的知识和数据,对不可见区域的空间结构有了更精准的把握。
在这一过程中,模型针对不可见区域的空间扭矩问题进行了深度学习和优化。通过大量的数据训练和算法优化,模型逐渐能够准确预测不可见区域的空间形态和布局,从而有效解决了空间扭矩问题。
最终,Wonderland 成功实现了保持高度 3D 一致的空间场景生成。所生成的 3D 场景不仅在视觉上给人以真实、连贯的感受,而且在空间结构上也具备高度的合理性和逻辑性。这一创新成果在虚拟现实、影视制作、游戏开发等众多领域都具有广泛的应用前景,为相关行业的发展提供了强大的技术支持和创新动力。