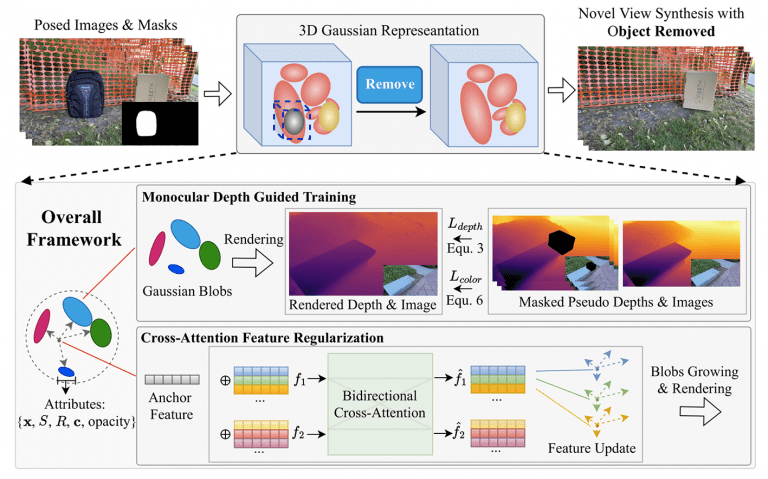
测评8款主流AI,AI “自信犯错”,我们还能否放心信赖?
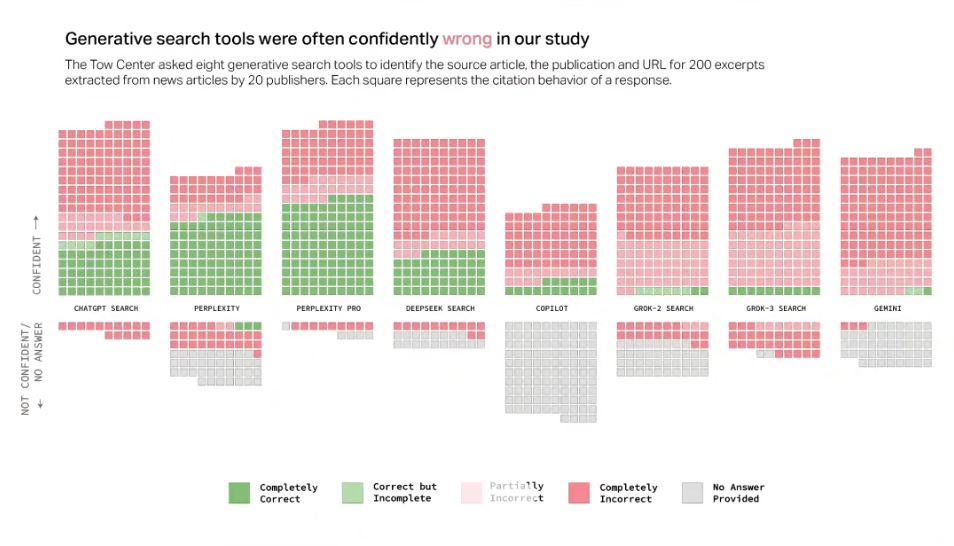
当 AI 开始 “自信满满” 地犯错,这着实让人大跌眼镜!哥伦比亚大学的一项测试,可谓是给 AI 界来了个 “大揭秘”。他们找来 8 款主流 AI 工具进行实时联网新闻搜索测试,结果令人咋舌,错误率高得惊人!
瞅瞅这张测试图,绿色代表完全正确部分。可现实残酷得很,62% 的查询结果都不准确!其中错误率最高的Grok3,竟高达 94%,简直 “错得离谱”;而正确率最高的是Perplexity的pro版本,咱们的 deepseek也不错,仅次于chatGPT,排名第三,。
为啥 AI 能错得如此理直气壮呢?研究发现,这些 AI 工具在面对无法回答的问题时,不是老老实实承认信息有限,而是用肯定语气编造答案。它们极少用 “可能”“也许” 这类模糊词,反而用确定性语言包装推测结果,这不是睁眼说瞎话嘛!
其实啊,在追求大模型智能的同时,信源质量愈发关键。就拿满血版的deepseek来说,在不同地方使用,回答结果差异明显,甚至 “味道” 都不一样。这就是因为不同平台信源不同,信源已然成为平台的核心壁垒。

不可否认,AI 搜索体验确实很棒,为我们节省了大量时间,那种便捷带来的 “爽感” 让不少人欲罢不能。但咱们得清醒,不能只沉浸在这种 “爽” 里。毕竟,AI 带来便捷的同时,也带来了错误风险。只有在体验与真相之间找到平衡,我们才能不被 AI 牵着鼻子走,始终保持清醒头脑,理性看待这些新兴技术,让 AI 真正为我们所用,而不是被其误导。不然,被 AI 的 “自信错误” 忽悠了,可就追悔莫及咯!